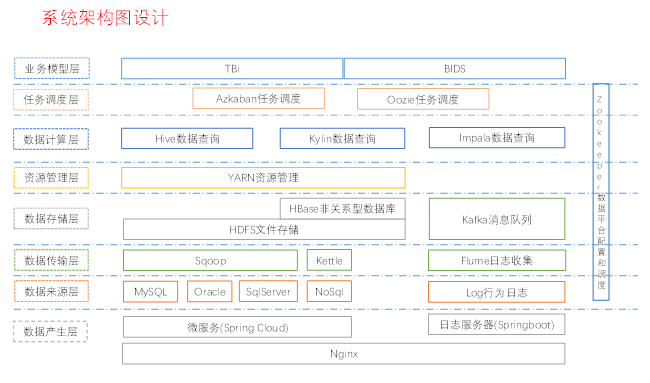
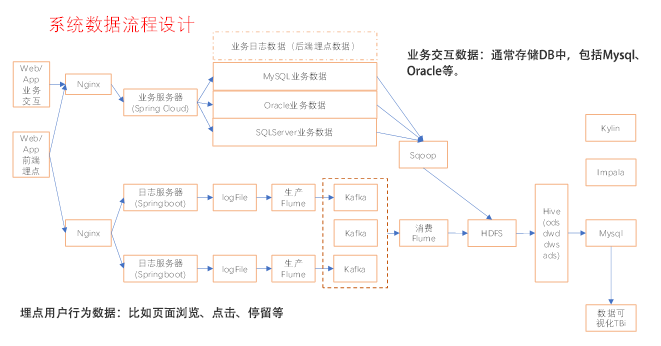
大数据平台 文档发布于:2020-02-27
一、大数据仓库衍生
没有数据仓库时,需要直接从业务数据库中取数据来做分析。在基于Spring Cloud微服务大环境下,大都数据分散、业务繁多,虽可用于分析,但需要做很多额外的调整,主要有以下几个问题:
结构复杂
业务数据库通常是根据业务操作的需要进行设计的,遵循3NF范式,尽可能减少数据冗余。这就造成表与表之间关系错综复杂。在分析业务状况时,储存业务数据的表,与储存想要分析的角度表,很可能不会直接关联,而是需要通过多层关联来达到,这为分析增加了很大的复杂度。
举例:想要从门店的地域分布来分析用户还款情况。基本的还款数据在订单细节表里,各种杂项信息在订单表里,门店信息在门店表里,地域信息在地域表里,这就意味着需要把这四张表关联起来,才能按门店地域来分析用户的还款情况,带来的问题就是多表复杂连接。
如节假日,URL,IP通常也不会在数据库中有记录,而是以文本文件的形式储存。多种多样的数据储存方式,也给取数带来了困难,没法简单地用一条SQL完成数据查询。如果能把这些数据都整合到一个数据库里,比如构造一张用户还款行为宽表、节假日宽表。这样就能很方便地完成数据查询,从而提高分析效率。
数据脏乱
因为业务数据库会接受大量用户的输入,如果业务系统没有做好足够的数据校验,就会产生一些错误数据,比如不合法的身份证号,或者不应存在的Null值,空字符串等。
缺少历史
出于节约空间的考虑,业务数据库通常不会记录状态流变历史,这就使得某些基于流变历史的分析无法进行。比如想要分析从用户申请到最终放款整个过程中,各个环节的速度和转化率,没有流变历史就很难完成。
大规模查询缓慢
当业务数据量较大时,查询就会变得缓慢。尤其需要同时关联好几张大表,比如还款表关联订单表再关联用户表,这个体量就非常巨大,查询速度非常慢。
二、大数据仓库要求
维护成本低
熟悉SQL开发的开发者可以很方便的使用进行开发。
高速查询
数据仓库本身并不提供高速查询功能。只是由于其简单的星形结构,比业务数据库的复杂查询在速度上更有优势。通过Impala、Kylin等内存计算,用空间换时间,即使是大数据规模也能实现毫秒级查询,大大提高工作效率;对于传统数据库来储存数据,同样也会遇到查询缓慢的问题。
结构清晰,简单
离线数据通常是一天变动一次,批量更新,由ETL系统完成。在这种情况下,数据的输入是高度可控的,对于即时数据建立临时表存储,执行完清除,可以尽可能地减少数据冗余,使用方便,易于理解,聚焦业务。
可复用,易拓展
典型的数据,用户画像,会跨业务线的多张进行汇总,这类主题表是业务数据的高度概括,基本上能满足业务团队80%以上的数据需求。拓展也十分方便,直接添加新的字段内容即可。
保存历史
构建拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期。如果当前信息至今有效,在生效结束日期中填入一个极大值。便于需要查看某些业务信息的某一个时间点当日的信息。
数据干净
在ETL过程中会去掉不干净的数据,使用起来更为方便。
三、基于Hadoop生态数据仓库优势
高可靠性
Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性
在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性
在MapReduce的思想下,Hadoop是并行工作的,基于Impala、Kylin的内存技术和多维分析,以加快任务处理速度,实现秒级查询。 不丢失
Flume的断点续传,Kafka的消息队列保证数据的高速安全传输不丢失。